La machine à produire des notes
Est-il prudent de céder le jugement évaluatif à un algorithme?


Photo de Raffaele Parente sur Unsplash
« Bien que de nombreuses approches de l’évaluation et de la notation puissent présenter un vernis d’objectivité, elles ne peuvent éviter les nombreux jugements subjectifs qui mènent à ce qui peut, à la fin du processus, sembler être une question purement technique. Même lorsque des procédures, des critères et des formules stricts sont appliqués d’une manière apparemment objective, le choix de ceux qui sont retenus repose sur des jugements humains. La variable ultime de référence est le consensus professionnel entre experts, fondé principalement sur l’analyse des travaux des élèves. Il n’existe rien de plus direct, rien de plus fondamental. » (Sadler, 2011, p. 89, traduction libre)
Dans la plupart des classes de l’enseignement supérieur au Québec, les enseignants et les enseignantes conçoivent pour leur cours un dispositif ayant pour but de produire une note finale tenant lieu de jugement au sujet des apprentissages des étudiants et des étudiantes. C’est la « machine à produire des notes ». Je ne parle pas ici de l’utilisation de l’intelligence artificielle générative pour corriger. Je réfère plutôt à une technologie pédagogique bien plus ancienne, l’utilisation d’un algorithme pour produire une note finale au terme d’un cours. C’est une « machine » assez artisanale, au sens où elle est composée en grande partie de rouages choisis par l’enseignante ou l’enseignant.
Je vous propose donc de porter un regard critique sur cette machine pour chercher à répondre à ces questions : de quoi est-elle faite? Pourquoi s’en sert-on? Et surtout, dans quelle mesure est-elle en mesure de produire un jugement valable de la compétence de nos étudiantes et étudiants?
De quoi est faite la machine?
En produisant son plan de cours, l’enseignant ou l’enseignante conçoit son dispositif d’évaluation et de notation. Les instruments et les contextes d’évaluation sont choisis, des pondérations sont attribuées. Souvent, plusieurs aspects de ce dispositif sont produits en cours de session. Les grilles d’évaluation, les examens, les critères et leur pondération, les barèmes de correction sont quelques-uns des éléments de ce dispositif.
En examinant d’encore plus près les engrenages qui animent cette machine, on pourrait voir, par exemple, que dans tel cours, des points sont attribués à chacune des questions d’un examen, et que pour chaque question de l’examen, des points sont attribués aux différentes étapes de la démarche de résolution de problème. Dans tel autre cours, une grille analytique est utilisée pour évaluer un travail en équipe, des points sont attribués pour chacun des critères évalués. Dans plusieurs cours, des points sont donnés pour des activités de nature formative, par exemple, des devoirs visant à préparer à des activités d’évaluation plus importantes. Des points sont retranchés pour un devoir manquant, un travail remis en retard : certains des rouages de la machine ont une visée de contrôle du comportement.
Un des engrenages de la machine est assez universel, au collégial : le calcul de la moyenne pondérée de la note à chacune des évaluations sommatives pour produire la note finale. C’est sans doute le plus important : toutes les autres pièces du mécanisme en découlent. Elles sont toutes tributaires de l’idée que des points sont accordés et additionnés tout au long de la session, et que le résultat de cette somme constitue la note finale.
Le recours à la moyenne pondérée est un élément du dispositif d’évaluation qui est non seulement presque systématique, mais il n’est pas questionné. Pourtant, les écrits sur l’évaluation soulignent le fait que le jugement évaluatif d’une compétence « ne peut se réduire à un simple calcul de moyenne pondérée » (Leroux & Bélair, 2015, p. 89). Son utilisation relève possiblement d’un déterminisme social et technique : la pratique est transmise, partagée, tenue pour acquise dans les politiques évaluatives des établissements d’enseignement (Voisard et al., 2025) et est même introduite par défaut à travers les outils informatiques pour communiquer les notes aux étudiants et étudiantes et aux institutions d’enseignement, tels que les plateformes Léa et Colnet, au niveau collégial au Québec.
Ainsi, si la réflexivité est une condition du développement professionnel chez le personnel enseignant (Conseil supérieur de l’éducation, 2014), le recours à la moyenne pondérée est souvent un point aveugle de son regard critique sur sa propre pratique.
Une des conséquences du recours à la moyenne pondérée
Nous l’avons remarqué ailleurs, le personnel enseignant et la population étudiante s’accordent généralement pour dire que la note finale devrait refléter l’état des apprentissages au terme de la session. Or, lorsque la note finale est calculée en ayant recours à un algorithme basé sur la moyenne pondérée de toutes les évaluations sommatives, la note finale dépend du parcours et pas uniquement de l’état final des apprentissages. Elle dépend aussi du choix de la pondération accordée à chacune des évaluations en cours de session. Les personnes qui ont du mal en début de session sont davantage pénalisées quand des pondérations plus importantes sont accordées plus tôt en session. Sadler (2010) l’illustre par des courbes d’apprentissage comme celles représentées à la figure ci-dessous.
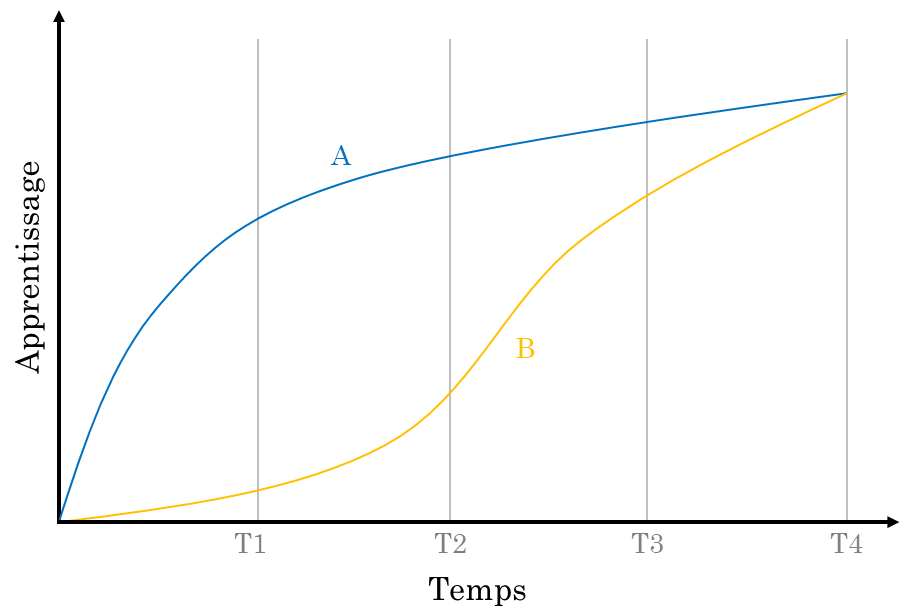
Figure 1 Deux courbes d’apprentissage hypothétiques. Adapté de Sadler (2010, p. 736).
Si la note finale est déterminée par l’addition de points récoltés aux temps 1, 2, 3 et 4, la personne A obtiendra une note plus élevée que la personne B, et ce, même si l’apprentissage de ces deux personnes au terme du cours est le même. Plus la pondération accordée aux temps 1 et 2 est importante, plus l’écart sera grand. L’algorithme lui-même influence donc la note finale. La démonstration de Sadler était théorique, mais elle se vérifie par des données réelles. Par exemple, celles décrites dans ce billet, qui ont été obtenues dans le cadre de nos travaux de recherche, démontrent que des étudiantes et étudiants dont les courbes d’apprentissage sont très différentes peuvent bel et bien terminer la session avec les mêmes apprentissages (Cormier et al., 2024).
Céder son jugement à un algorithme
Ainsi, dans la plupart des classes, le dispositif lui-même produit une note qui tient lieu de jugement sur le degré d’atteinte des cibles d’apprentissage. C’est bien l’enseignante ou l’enseignant qui crée le dispositif qui produira la note, mais une fois qu’il est lancé, c’est ce dispositif qui, alimenté par des données, produit une valeur, la note, qui tient lieu de jugement évaluatif. La responsabilité de poser un jugement global est cédée en amont au dispositif, et la ou le prof en est réduit à poser des micro-jugements destinés à générer les données qui alimentent l’algorithme. Ces micro-jugements portent sur des questions isolées, des étapes individuelles dans des démarches de résolution de problème, le degré de respect de critères isolés dans le contexte de performances isolées, etc.
La mise en place de cet algorithme fait perdre de vue la capacité de réaliser ou non les tâches visées et génère de nombreuses situations de désalignement entre la note et les cibles d’apprentissage. Ce phénomène est ce qui fait dire à Raphaël Pasquini que «[l]’évaluation notée est excessive : les acteurs ne réfléchissent plus à ce qu’ils souhaitent évaluer» (2021, p. 23) et que «[l]es échelles en pourcentages ne fonctionnent que sur l’exactitude des calculs des seuils des notes, sans rapport avec la maîtrise avérée des apprentissages des élèves dans les tâches évaluatives» (2021, p. 32).
La mise en place de l’algorithme constitue ainsi une inversion du rôle de la note et du jugement évaluatif, de la cause et de l’effet. Le jugement devient une conséquence de la note plutôt que l’inverse : avec l’échelle en pourcentage, si l’algorithme produit une valeur de 60 ou plus, la personne est réputée compétente, quand c’est plutôt une personne jugée compétente qui devrait obtenir une note de 60 % ou plus - la note de passage étant fixée par règlement à 60 % au collégial québécois (Biggs & Tang, 2011; Conseil supérieur de l’éducation, 2018; Sadler, 2013; Scallon, 2004; Tardif, 2006).
Pourquoi avoir recours à l’algorithme?
En admettant que le personnel enseignant fait preuve de réflexivité, si le recours à un algorithme lui posait problème, on doit admettre qu’il chercherait à noter autrement. Quelles raisons peuvent donc expliquer pourquoi il délègue volontiers son jugement évaluatif? Sans prétendre en faire l’inventaire complet, voici quelques-unes des raisons possibles de ce choix.
D’abord, en appliquant un processus uniforme et relativement transparent pour produire la note finale, on souhaite minimiser les biais et, par ricochet, éviter les conflits relatifs à l’évaluation avec les étudiants et étudiantes – ce qui échoue cependant parfois. Autrement dit, la machine nous convient parce qu’on croit en son objectivité. Les décisions subjectives sont cachées dans le choix des engrenages. Nous sommes aveugles au caractère inéquitable et biaisé du résultat.
Ensuite, l’usage d’un algorithme permet même au personnel enseignant qui n’a pas d’autre formation en évaluation et en notation que sa propre expérience scolaire de produire une note finale. Puisqu’à l’enseignement supérieur, il n’est souvent pas nécessaire d’avoir une formation pédagogique pour enseigner, cet aspect n’est pas négligeable.
L’algorithme permet de produire une note finale sans qu’il ne soit nécessaire de se demander au préalable ce dont devrait être capable une personne compétente. En effet, la compétence est définie sur la base d’une machine qui n’a pas à être calibrée : quand elle produit une note de 60 % ou plus, la personne est décrétée compétente.
Les systèmes informatiques utilisés au collégial pour consigner les notes, comme Léa et Colnet, sont biaisés vers l’application des règles de base de la machine, soit de donner une note numérique à chaque évaluation et de produire une note finale sur la base d’une moyenne pondérée de chacune d’entre elles. Avec Léa, les commentaires qualitatifs ne peuvent même pas être consultés par les étudiants et étudiantes si aucune note numérique n’est fournie! Bruno Latour, sociologue des sciences, aurait probablement dit que ces systèmes informatiques incarnent une norme sociale (Latour, 1992). Ces « acteurs sociaux » non humains contribuent à ce que cette norme soit si difficile à changer, malgré qu’elle ne corresponde plus à ce que recommandent les écrits sur l’évaluation depuis des décennies (Howe & Ménard, 1993).
Au collégial québécois, par règlement, la note finale des cours doit être exprimée en pourcentage. Cette contrainte, combinée avec l’impossibilité humaine de distinguer avec justesse 101 niveaux de performance, peut inciter à avoir recours à un algorithme qui donne une illusion d’objectivité.
L’imposition par les institutions d’enseignement et les départements de règles qui réfèrent à des opérations mathématiques pour altérer la note pour différents facteurs (pénalités de retard, pour la langue, pour un travail non remis, etc.) est un autre incitatif à la construction d’un algorithme pour produire une note finale.
En guise de conclusion : quelques pistes de solution
La solution naïve pour éviter que la note finale ne dépende du parcours et de l’algorithme choisi, et pour faire en sorte qu’elle dépende uniquement de l’état final des apprentissages, est d’accorder 100 % de la pondération à une évaluation placée à la toute fin de la session. Bien sûr, cela pose problème du point de vue du soutien aux apprentissages (Howe, 2006). Or, l’évaluation ne vise pas seulement à témoigner de l’état des apprentissages. Elle doit d’abord servir à les soutenir (Conseil supérieur de l’éducation, 2018). La solution pour que la note soit au service de ces deux finalités de l’évaluation, c’est de la composer sur la base des traces les plus représentatives des apprentissages plutôt que sur la sommation de toutes les évaluations dites sommatives. La solution, c’est avoir recours à ce que nous désignons sous le nom de PAN.
Nous pourrions le présenter autrement, en disant qu’il faut « simplement » redonner sa place au jugement évaluatif, au détriment de la « machine », de l’algorithme. Bien que Pierre Flynn était étudiant de cégep au moment de les écrire, il ne référait pas à la note lorsqu’il écrivait les paroles de la chanson La maudite machine, du groupe Octobre. Je les cite tout de même parce qu’elles illustrent joliment cette idée:
« La maudite machine
Qui t’a avalé
A marche en câline
Faudrait la casser
Faudrait la casser »
Parmi les solutions qui s’offrent à nous pour redonner graduellement sa place au jugement évaluatif pour évaluer les compétences, il y a le recours à un seuil minimal de réussite. Il permet de rétablir la relation de cause à effet entre le jugement du développement de la compétence et l’obtention d’une note de 60 % et plus. Ensuite, si au collégial, la note finale doit être exprimée en pourcentage, rien n’impose d’utiliser les 101 niveaux de cette échelle. On peut se contenter de restreindre le nombre de niveaux à un nombre qui peut être humainement distingué, ou même, quand notre contexte le permet, le réduire à deux niveaux.
Les pratiques alternatives de notation regroupent un éventail de façons de noter. Y avoir recours en prenant soin de choisir le système de notation le plus approprié en fonction du contexte, c’est se donner réellement la possibilité d’exprimer son jugement évaluatif. C’est se permettre de ne plus avoir de point aveugle sur sa pratique réflexive. Et travailler avec les PAN, selon notre propre expérience, nous permet de solliciter davantage la collaboration entre collègues pour réfléchir à l’ensemble du processus d’évaluation, de la définition des cibles d’apprentissage à l’étape d’établir les notes finales. L’intersubjectivité soutient le développement du jugement évaluatif et constitue, contrairement à l’algorithme, un véritable rempart contre l’arbitraire – comme le rappelle Sadler dans la citation en ouverture de ce billet.
Références
Biggs, J. B., & Tang, C. S. (2011). Teaching for quality learning at university : What the student does (4th edition). McGraw-Hill/Society for Research into Higher Education/Open University Press.
Conseil supérieur de l’éducation. (2014). Le développement professionnel, un enrichissement pour toute la profession enseignante : Avis au ministre de l’Éducation, du loisir et du sport et ministre de l’Enseignement supérieur, de la recherche et de la science (C. Lebossé & F. Richard, Éds.). Conseil supérieur de l’éducation.
Conseil supérieur de l’éducation. (2018). Rapport sur l’état et les besoins de l’éducation 2016-2018 – Évaluer pour que ça compte vraiment. Gouvernement du Québec. https://www.cse.gouv.qc.ca/wp-content/uploads/2020/01/50-0508-RF-evaluer-compte-vraiment-REBE-16-18.pdf
Cormier, C., Voisard, B., Arseneault-Hubert, F., & Turcotte, V. (2024, mai). Les pratiques alternatives de notation en enseignement supérieur : Rétablir le balancier des finalités de l’évaluation en améliorant le soutien à l’apprentissage. 91e congrès de l’Acfas. https://www.acfas.ca/evenements/congres/91/contribution/pratiques-alternatives-notation-enseignement-superieur-retablir
Howe, R. (2006). La note de l’évaluation finale d’un cours dans l’approche par compétence : Quelques enjeux pédagogiques. Pédagogie collégiale, 20(1), 10‑15. https://eduq.info/xmlui/bitstream/handle/11515/21607/RobertHowe_20_1.pdf
Howe, R., & Ménard, L. (1993). Un nouveau paradigme en évaluation des apprentissages. 6. https://eduq.info/xmlui/bitstream/handle/11515/21313/howe_menard_06_3.pdf
Latour, B. (1992). Where Are the Missing Masses ? The Sociology of a Few Mundane Artifacts. Dans W. E. Bijker & J. Law (Éds.), Shaping technology/building society : Studies in sociotechnical change. MIT Press.
Leroux, J. L., & Bélair, L. (2015). Exercer son jugement professionnel en enseignement supérieur. Dans J. L. Leroux, Évaluer les compétences au collégial et à l’université : Un guide pratique (p. 65‑104). AQPC.
Pasquini, R. (2021). Quand la note devient constructive. Évaluer pour certifier et soutenir les apprentissages. Les Presses de l’Université Laval.
Sadler, D. R. (2010). Fidelity as a precondition for integrity in grading academic achievement. Assessment & Evaluation in Higher Education, 35(6), 727‑743. https://doi.org/10.1080/02602930902977756
Sadler, D. R. (2011). Academic freedom, achievement standards and professional identity. Quality in Higher Education, 17(1), 85‑100. https://doi.org/10.1080/13538322.2011.554639
Sadler, D. R. (2013). Making Competent Judgments of Competence. Dans S. Blömeke, O. Zlatkin-Troitschanskaia, C. Kuhn, & J. Fege (Éds.), Modeling and Measuring Competencies in Higher Education (p. 13‑27). SensePublishers. https://doi.org/10.1007/978-94-6091-867-4_2
Scallon, G. (2004). L’évaluation des apprentissages dans une approche par compétences. ERPI.
Tardif, J. (2006). L’évaluation des compétences : Documenter le parcours de développement. Chenelière.
Voisard, B., Cormier, C., Turcotte, V., & Arseneault-Hubert, F. (2025). Vers une note plus juste et plus équitable : Comment les PIEA orientent-elles nos actions? Pédagogie collégiale, 39(1), 16‑25. https://eduq.info/xmlui/bitstream/handle/11515/40092/Voisard-et-al-39-1-25.pdf